cd.models
This submodule contains model definitions and common modules.
U-Net
- class BackboneAsUNet(backbone, return_layers, in_channels_list, out_channels, block, block_kwargs: dict | None = None, final_activation=None, interpolate='nearest', ilg=None, nd=2, in_strides_list=None, **kwargs)
- forward(inputs)
- class ConvNeXtBaseUNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
ConvNeXt Base U-Net.
A U-Net with ConvNeXt Base encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ConvNeXtLargeUNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
ConvNeXt Large U-Net.
A U-Net with ConvNeXt Large encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ConvNeXtSmallUNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
ConvNeXt Small U-Net.
A U-Net with ConvNeXt Small encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ConvNeXtTinyUNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
ConvNeXt Tiny U-Net.
A U-Net with ConvNeXt Tiny encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ExtraUNetBlock(out_channels: Tuple[int], out_strides: Tuple[int])
- forward(results: List[Tensor], x: List[Tensor], names: List[str]) Tuple[List[Tensor], List[str]]
- class GeneralizedUNet(in_channels_list, out_channels: int, block_cls: Module, block_kwargs: dict | None = None, final_activation=None, interpolate='nearest', final_interpolate=None, initialize=True, keep_features=True, bridge_strides=True, bridge_block_cls: Module | None = None, bridge_block_kwargs: dict | None = None, secondary_block: Module | None = None, in_strides_list: List[int] | Tuple[int] | None = None, out_channels_list: List[int] | Tuple[int] | None = None, nd=2, **kwargs)
- forward(x: Dict[str, Tensor], size: List[int]) Dict[str, Tensor] | Tensor
- Parameters:
x –
- Input dictionary. E.g. {
0: Tensor[1, 64, 128, 128] 1: Tensor[1, 128, 64, 64] 2: Tensor[1, 256, 32, 32] 3: Tensor[1, 512, 16, 16]
}
size – Desired final output size. If set to None output remains as it is.
- Returns:
Output dictionary. For each key in x a corresponding output is returned; the final output has the key ‘out’. E.g. {
out: Tensor[1, 2, 128, 128] 0: Tensor[1, 64, 128, 128] 1: Tensor[1, 128, 64, 64] 2: Tensor[1, 256, 32, 32] 3: Tensor[1, 512, 16, 16]
}
- class IntermediateUNetBlock(out_channels: Tuple[int], out_strides: Tuple[int])
- forward(x: Dict[str, Tensor]) Dict[str, Tensor]
- class MobileNetV3LargeUNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Large MobileNet V3 U-Net.
A U-Net with Large MobileNet V3 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class MobileNetV3SmallUNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Small MobileNet V3 U-Net.
A U-Net with Small MobileNet V3 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNeXt101UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNeXt 101 U-Net.
A U-Net with ResNeXt 101 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNeXt152UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNeXt 152 U-Net.
A U-Net with ResNeXt 152 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNeXt50UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNeXt 50 U-Net.
A U-Net with ResNeXt 50 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNet101UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNet 101 U-Net.
A U-Net with ResNet 101 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNet152UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNet 152 U-Net.
A U-Net with ResNet 152 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNet18UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNet 18 U-Net.
A U-Net with ResNet 18 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNet34UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNet 34 U-Net.
A U-Net with ResNet 34 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResNet50UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
ResNet 50 U-Net.
A U-Net with ResNet 50 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class ResUNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Residual U-Net.
U-Net with residual blocks.
References
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function.
backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
ResBlock.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class SlimU22(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Slim U-Net 22.
U-Net with 22 convolutions on 5 feature resolutions (1, 1/2, 1/4, 1/8, 1/16) and one final output layer. Like U22, but number of feature channels reduce by half.
References
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class SmpUNet(in_channels, out_channels, model_name, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
SmpEncoder U-Net.
A U-Net with SmpEncoder encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class TimmUNet(in_channels, out_channels, model_name, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
TimmEncoder U-Net.
A U-Net with TimmEncoder encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class U12(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
U-Net 12.
U-Net with 12 convolutions on 3 feature resolutions (1, 1/2, 1/4) and one final output layer.
References
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class U17(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
U-Net 17.
U-Net with 17 convolutions on 4 feature resolutions (1, 1/2, 1/4, 1/8) and one final output layer.
References
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class U22(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
U-Net 22.
U-Net with 22 convolutions on 5 feature resolutions (1, 1/2, 1/4, 1/8, 1/16) and one final output layer.
References
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function.
backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class UNet(backbone, out_channels: int, return_layers: dict | None = None, block: Type[Module] | None = None, block_kwargs: dict | None = None, final_activation=None, interpolate='nearest', nd=2, **kwargs)
U-Net.
References
- Parameters:
backbone – Backbone instance.
out_channels – Output channels. If set to
0, the output layer is omitted.return_layers – Return layers used to extract layer features from backbone. Dictionary like {backbone_layer_name: out_name}. Note that this influences how outputs are computed, as the input for the upsampling is gathered by IntermediateLayerGetter based on given dict keys.
block – Main block. Default:
TwoConvNormRelu.block_kwargs – Block keyword arguments.
final_activation – Final activation function.
interpolate – Interpolation.
nd – Spatial dimensions.
**kwargs – Additional keyword arguments.
- class UNetEncoder(in_channels, depth=5, base_channels=64, factor=2, pool=True, block_cls: Type[Module] | None = None, nd=2)
U-Net Encoder.
- Parameters:
in_channels – Input channels.
depth – Model depth.
base_channels – Base channels.
factor – Growth factor of base_channels.
pool – Whether to use max pooling or stride 2 for downsampling.
block_cls – Block class. Callable as block_cls(in_channels, out_channels, stride=stride).
- class WideResNet101UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Wide ResNet 101 U-Net.
A U-Net with Wide ResNet 101 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class WideResNet50UNet(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Wide ResNet 50 U-Net.
A U-Net with Wide ResNet 50 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
- class WideU22(in_channels, out_channels, final_activation=None, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Slim U-Net 22.
U-Net with 22 convolutions on 5 feature resolutions (1, 1/2, 1/4, 1/8, 1/16) and one final output layer. Like U22, but number of feature channels doubled.
References
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_activation – Final activation function. Only used if
out_channels > 0.backbone_kwargs – Keyword arguments for encoder.
pretrained – Whether to use a pretrained encoder. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.block_cls – Module class that defines a convolutional block. Default:
TwoConvNormRelu.**kwargs – Additional keyword arguments for
cd.models.UNet.
Multi-Scale Attention Network
- class MaNet(backbone, out_channels: int = 0, pab_channels=64, block: Type[Module] | None = None, block_kwargs: dict | None = None, final_activation=None, interpolate='nearest', nd=2, **kwargs)
Multi-Scale Attention Network.
A U-Net variant using a generic encoder and a special decoder that includes a Position-wise Attention Block (PAB) and several Multi-scale Fusion Attention Blocks (MFAB).
References
- Parameters:
backbone – Backbone instance.
out_channels – Output channels. If set to
0, the output layer is omitted.pab_channels – Channels of the Position-wise Attention Block (PAB).
block – Main block. Default: Multi-scale Fusion Attention Block (MFAB).
block_kwargs – Block keyword arguments.
final_activation – Final activation function.
interpolate – Interpolation.
nd – Spatial dimensions.
**kwargs – Additional keyword arguments.
- class MultiscaleFusionAttention(in_channels, in_channels2, out_channels, norm_layer='BatchNorm2d', activation='relu', compression=16, interpolation=None, nd=2)
- forward(x, x2=None)
- class PositionWiseAttention(in_channels, out_channels, mid_channels=64, kernel_size=3, padding=1, beta=False, nd=2)
- forward(inputs)
- class SmpMaNet(in_channels, out_channels, model_name, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
- class TimmMaNet(in_channels, out_channels, model_name, final_activation=None, backbone_kwargs=None, pretrained=True, block_cls=None, nd=2, **kwargs)
Contour Proposal Network
- class CPN(backbone: Module, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, certainty_thresh: float | None = None, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, contour_features='1', location_features='1', uncertainty_features='1', score_features='1', refinement_features='0', uncertainty_head=False, uncertainty_nms=False, uncertainty_factor=7.0, contour_head_channels=None, contour_head_stride=1, order_weights=True, refinement_head_channels=None, refinement_head_stride=1, refinement_interpolation='bilinear', **kwargs)
CPN base class.
This is the base class for the Contour Proposal Network.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
backbone – A backbone network. E.g.
cd.models.U22(in_channels, 0).order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.contour_features – If
backbonereturns a dictionary of features, this is the key used to retrieve the features that are used to predict contours.refinement_features – If
backbonereturns a dictionary of features, this is the key used to retrieve the features that are used to predict the refinement tensor.contour_head_channels – Number of intermediate channels in contour
ReadOutModules. By default, this is the number of incoming feature channels.contour_head_stride – Stride used for the contour prediction. Larger stride means less contours can be proposed in total, which speeds up execution times.
order_weights – Whether to use order specific weights.
refinement_head_channels – Number of intermediate channels in refinement
ReadOutModules. By default, this is the number of incoming feature channels.refinement_head_stride – Stride used for the refinement prediction. Larger stride means less detail, but speeds up execution times.
refinement_interpolation – Interpolation mode that is used to ensure that refinement tensor and input image have the same shape.
score_encoder_features – Whether to use encoder-head skip connections for the score head.
refinement_encoder_features – Whether to use encoder-head skip connections for the refinement head.
- compute_loss(uncertainty, fourier, locations, contours, refined_contours, all_refined_contours, boxes, raw_scores, targets: dict, labels, fg_masks, sampling, b)
- forward(inputs, targets: Dict[str, Tensor] | None = None, nms=True, **kwargs)
- class CpnConvNeXtBaseUNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ConvNeXt Base U-Net backbone.
A Contour Proposal Network that uses a ConvNeXt Base U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ConvNeXtBaseUNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnConvNeXtLargeUNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ConvNeXt Large U-Net backbone.
A Contour Proposal Network that uses a ConvNeXt Large U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ConvNeXtLargeUNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnConvNeXtSmallUNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ConvNeXt Small U-Net backbone.
A Contour Proposal Network that uses a ConvNeXt Small U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ConvNeXtSmallUNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnConvNeXtTinyUNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ConvNeXt Tiny U-Net backbone.
A Contour Proposal Network that uses a ConvNeXt Tiny U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ConvNeXtTinyUNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnMiTB5MaNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Mix Transformer encoder and Multi-Scale Attention Network decoder as backbone.
A Contour Proposal Network that uses a Mix Transformer B5 encoder with the Multi-Scale Attention Network decoder as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.CpnMiTB5MaNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnMobileNetV3LargeFPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Large MobileNetV3 FPN backbone.
A Contour Proposal Network that uses a Large MobileNetV3 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.MobileNetV3LargeFPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnMobileNetV3SmallFPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Small MobileNetV3 FPN backbone.
A Contour Proposal Network that uses a Small MobileNetV3 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.MobileNetV3SmallFPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNeXt101FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNeXt 101 FPN backbone.
A Contour Proposal Network that uses a ResNeXt 101 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNeXt101FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNeXt101UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNeXt 101 U-Net backbone.
A Contour Proposal Network that uses a ResNeXt 101 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNeXt101UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNeXt152FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNeXt 152 FPN backbone.
A Contour Proposal Network that uses a ResNeXt 152 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNeXt152FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNeXt152UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNeXt 152 U-Net backbone.
A Contour Proposal Network that uses a ResNet 152 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNeXt152UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNeXt50FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNeXt 50 FPN backbone.
A Contour Proposal Network that uses a ResNeXt 50 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNeXt50FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNeXt50UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNeXt 50 U-Net backbone.
A Contour Proposal Network that uses a ResNeXt 50 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNeXt50UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet101FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNet 101 FPN backbone.
A Contour Proposal Network that uses a ResNet 101 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet101FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet101UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNet 101 U-Net backbone.
A Contour Proposal Network that uses a ResNet 101 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet101UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet152FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNet 152 FPN backbone.
A Contour Proposal Network that uses a ResNet 152 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet152FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet152UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNet 152 U-Net backbone.
A Contour Proposal Network that uses a ResNet 152 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet152UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet18FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNet 18 FPN backbone.
A Contour Proposal Network that uses a ResNet 18 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet18FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet18UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNet 18 U-Net backbone.
A Contour Proposal Network that uses a ResNet 18 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet18UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet34FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNet 34 FPN backbone.
A Contour Proposal Network that uses a ResNet 34 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet34FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet34UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNet 34 U-Net backbone.
A Contour Proposal Network that uses a ResNet 34 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet34UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet50FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with ResNet 50 FPN backbone.
A Contour Proposal Network that uses a ResNet 50 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet50FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResNet50UNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with ResNet 50 U-Net backbone.
A Contour Proposal Network that uses a ResNet 50 U-Net as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResNet50UNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnResUNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Residual U-Net backbone.
A Contour Proposal Network that uses a U-Net build with residual blocks.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.ResUNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnSlimU22(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Slim U-Net 22 backbone.
A Contour Proposal Network that uses a Slim U-Net as a backbone. Slim U-Net has 22 convolutions with less feature channels than normal U22.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.SlimU22.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnSmpMaNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with MA-Net and a backbone from the smp package.
A Contour Proposal Network that uses MA-Net and a backbone from the smp package.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.SmpMaNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnSmpUNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with a U-Net and a backbone from the smp package.
A Contour Proposal Network that uses a U-Net and a backbone from the smp package.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.SmpUNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnTimmMaNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with MA-Net and a backbone from the timm package.
A Contour Proposal Network that uses a MA-Net and a backbone from the timm package.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.TimmMaNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnTimmUNet(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs=None, **kwargs)
Contour Proposal Network with a U-Net and a backbone from the timm package.
A Contour Proposal Network that uses a U-Net and a backbone from the timm package.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.TimmUNet.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnU22(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with U-Net 22 backbone.
A Contour Proposal Network that uses a U-Net with 22 convolutions as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.U22.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnWideResNet101FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Wide ResNet 101 FPN backbone.
A Contour Proposal Network that uses a Wide ResNet 101 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.WideResNet101FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnWideResNet50FPN(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Wide ResNet 50 FPN backbone.
A Contour Proposal Network that uses a Wide ResNet 50 Feature Pyramid Network as a backbone.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.WideResNet50FPN.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
- class CpnWideU22(in_channels: int, order: int = 5, nms_thresh: float = 0.2, score_thresh: float = 0.9, samples: int = 32, classes: int = 2, refinement: bool = True, refinement_iterations: int = 4, refinement_margin: float = 3.0, refinement_buckets: int = 1, backbone_kwargs: dict | None = None, **kwargs)
Contour Proposal Network with Wide U-Net 22 backbone.
A Contour Proposal Network that uses a Wide U-Net as a backbone. Wide U-Net has 22 convolutions with more feature channels than normal U22.
References
https://www.sciencedirect.com/science/article/pii/S136184152200024X
- Parameters:
in_channels – Number of input channels.
order – Contour order. The higher, the more complex contours can be proposed.
order=1restricts the CPN to propose ellipses,order=3allows for non-convex rough outlines,order=8allows even finer detail.nms_thresh – IoU threshold for non-maximum suppression (NMS). NMS considers all objects with
iou > nms_threshto be identical.score_thresh – Score threshold. For binary classification problems (object vs. background) an object must have
score > score_threshto be proposed as a result.samples – Number of samples. This sets the number of coordinates with which a contour is defined. This setting can be changed on the fly, e.g. small for training and large for inference. Small settings reduces computational costs, while larger settings capture more detail.
classes – Number of classes. Default: 2 (object vs. background).
refinement – Whether to use local refinement or not. Local refinement generally improves pixel precision of the proposed contours.
refinement_iterations – Number of refinement iterations.
refinement_margin – Maximum refinement margin (step size) per iteration.
refinement_buckets – Number of refinement buckets. Bucketed refinement is especially recommended for data with overlapping objects.
refinement_buckets=1practically disables bucketing,refinement_buckets=6uses 6 different buckets, each influencing different fractions of a contour.backbone_kwargs – Additional backbone keyword arguments. See docstring of
cd.models.WideU22.**kwargs – Additional CPN keyword arguments. See docstring of
cd.models.CPN.
ResNet
- class ResNeXt101_32x8d(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
ResNeXt 101.
ResNeXt 101 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class ResNeXt152_32x8d(in_channels, out_channels=0, nd=2, **kwargs)
ResNeXt 152.
ResNeXt 152 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class ResNeXt50_32x4d(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
ResNeXt 50.
ResNeXt 50 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class ResNet101(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
ResNet 101.
ResNet 101 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class ResNet152(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
ResNet 152.
ResNet 152 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class ResNet18(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
ResNet 18.
ResNet 18 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class ResNet34(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
ResNet 34.
ResNet 34 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class ResNet50(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
ResNet 50.
ResNet 50 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class WideResNet101_2(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
Wide ResNet 101.
Wide ResNet 101 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- class WideResNet50_2(in_channels, out_channels=0, pretrained=False, nd=2, **kwargs)
Wide ResNet 50.
Wide ResNet 50 encoder.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels. If set to 0, the output layer is omitted.
final_layer – Final output layer. Default: 1x1 Conv2d if
out_channels >= 1,Noneotherwise.final_activation – Final activation layer (e.g.
nn.ReLUor'relu'). Default:None.pretrained – Whether to load weights from a pretrained network. If True default weights are used. Alternatively,
pretrainedcan be a URL of astate_dictthat is hosted online.**kwargs – Additional keyword arguments.
- get_resnet(name, in_channels, **kwargs)
Feature Pyramid Network
- class ConvNeXtBaseFPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ConvNeXtLargeFPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ConvNeXtSmallFPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ConvNeXtTinyFPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class FPN(backbone, channels=256, return_layers: dict | None = None, **kwargs)
Examples
>>> from celldetection.models import ResNet18, FPN ... import torch >>> model = FPN(ResNet18(in_channels=1)) >>> for k, v in model(torch.rand(1, 1, 128, 128)).items(): ... print(k, " ", v.shape) 0 torch.Size([1, 256, 32, 32]) 1 torch.Size([1, 256, 16, 16]) 2 torch.Size([1, 256, 8, 8]) 3 torch.Size([1, 256, 4, 4]) pool torch.Size([1, 256, 2, 2])
- Parameters:
backbone – Backbone module Note that backbone.out_channels must be defined.
channels – Channels in the upsampling branch.
return_layers – Dictionary like {backbone_layer_name: out_name}. Note that this influences how outputs are computed, as the input for the upsampling is gathered by IntermediateLayerGetter based on given dict keys.
- class MobileNetV3LargeFPN(in_channels, fpn_channels=256, nd=2, **kwargs)
Feature Pyramid Network with MobileNetV3Large.
Examples
>>> import torch >>> from celldetection import models >>> model = models.MobileNetV3LargeFPN(in_channels=3) >>> out: dict = model(torch.rand(1, 3, 256, 256)) >>> for k, v in out.items(): ... print(k, v.shape) 0 torch.Size([1, 256, 128, 128]) 1 torch.Size([1, 256, 64, 64]) 2 torch.Size([1, 256, 32, 32]) 3 torch.Size([1, 256, 16, 16]) 4 torch.Size([1, 256, 8, 8]) pool torch.Size([1, 256, 4, 4])
- class MobileNetV3SmallFPN(in_channels, fpn_channels=256, nd=2, **kwargs)
Feature Pyramid Network with MobileNetV3Small.
Examples
>>> import torch >>> from celldetection import models >>> model = models.MobileNetV3SmallFPN(in_channels=3) >>> out: dict = model(torch.rand(1, 3, 256, 256)) >>> for k, v in out.items(): ... print(k, v.shape) 0 torch.Size([1, 256, 128, 128]) 1 torch.Size([1, 256, 64, 64]) 2 torch.Size([1, 256, 32, 32]) 3 torch.Size([1, 256, 16, 16]) 4 torch.Size([1, 256, 8, 8]) pool torch.Size([1, 256, 4, 4])
- class ResNeXt101FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ResNeXt152FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ResNeXt50FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ResNet101FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ResNet152FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ResNet18FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ResNet34FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class ResNet50FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class SmpFPN(in_channels, model_name, fpn_channels=256, backbone_kwargs=None, pretrained=True, **kwargs)
- class TimmFPN(in_channels, model_name, fpn_channels=256, backbone_kwargs=None, pretrained=True, **kwargs)
- class WideResNet101FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
- class WideResNet50FPN(in_channels, fpn_channels=256, backbone_kwargs=None, pretrained=False, block_cls=None, nd=2, **kwargs)
Timm Encoder
- class TimmEncoder(model_name: str, in_channels: int = 3, return_layers: List[str] | None = None, out_channels: List[str] | None = None, out_strides: List[str] | None = None, pretrained: bool = False, pretrained_cfg=None, keep_names: bool = False, output_stride: int | None = None, depth: int | None = None, convert_lists: bool = True, **kwargs)
Timm Encoder.
A wrapper that provides compatibility with “PyTorch Image Models (timm)”.
Notes
It is possible to customize TimmEncoder`s return_layers to return specific layer outputs. In that case
out_channelsandout_stridesmust be provided. To find appropriate settings the helper functionsget_namesandget_channels_stridescan be used.References
timm GitHub: https://github.com/huggingface/pytorch-image-models
timm Documentation: https://huggingface.co/docs/timm/index
Examples
>>> import timm, celldetection as cd >>> timm.list_models('*darknet*') # discover models ['cs3darknet_focus_l', 'cs3darknet_focus_m', 'cs3darknet_focus_s', 'cs3darknet_focus_x', 'cs3darknet_l', 'cs3darknet_m', 'cs3darknet_s', 'cs3darknet_x', 'cs3sedarknet_l', 'cs3sedarknet_x', 'cs3sedarknet_xdw', 'cspdarknet53', 'darknet17', 'darknet21', 'darknet53', 'darknetaa53', 'sedarknet21'] >>> encoder = cd.models.TimmEncoder('darknet21') >>> encoder.out_channels ... [32, 64, 128, 256, 512, 1024] >>> encoder.out_strides ... [1, 2, 4, 8, 16, 32] >>> output: Dict[str, Tensor] = encoder(torch.rand(1, 3, 512, 512)) >>> for key, layer_output in output.items(): ... print(key, layer_output.shape) 0 torch.Size([1, 32, 512, 512]) 1 torch.Size([1, 64, 256, 256]) 2 torch.Size([1, 128, 128, 128]) 3 torch.Size([1, 256, 64, 64]) 4 torch.Size([1, 512, 32, 32]) 5 torch.Size([1, 1024, 16, 16])
- Parameters:
model_name – Name of model to instantiate.
return_layers – List of layer names used for intermediate feature retrieval.
out_channels – List of output channels per return layer.
out_strides – List of output strides per return layer.
pretrained – Whether to load pretrained ImageNet-1k weights.
pretrained_cfg – External pretrained_cfg for model.
keep_names – Whether to keep layer names for model output. If
False, names are replaced with enumeration for consistency.output_stride – Some models support different output stride (e.g. 16 instead of 32). This is achieved by using
stride=1with dilation instead of downsampling with strides.depth – Custom encoder depth. If return_layers provided, this acts as number of return layers.
convert_lists – Whether to return output lists to dictionaries for consistency.
**kwargs – Keyword arguments for
timm.create_modelcall.
- forward(x)
Smp Encoder
- class SmpEncoder(model_name: str, in_channels: int = 3, depth: int = 5, pretrained=False, output_stride: int = 32, **kwargs)
Smp Encoder.
A wrapper that provides compatibility with “segmentation_models_pytorch (smp)”.
References
smp GitHub: https://github.com/qubvel/segmentation_models.pytorch
Encoders: https://smp.readthedocs.io/en/latest/encoders.html
Documentation: https://smp.readthedocs.io/en/latest/
- Parameters:
model_name – Encoder name. Find available encoders here: https://smp.readthedocs.io/en/latest/encoders.html
in_channels – Input channels.
depth – Encoder dpeth.
pretrained – Encoder weights. Find available weights here: https://smp.readthedocs.io/en/latest/encoders.html
output_stride – Output stride.
**kwargs
- forward(x, *args, **kwargs)
ConvNeXt
- class CNBlock(in_channels, out_channels=None, layer_scale: float = 1e-06, stochastic_depth_prob: float = 0, norm_layer: Callable[[...], Module] | None = None, activation='gelu', stride: int = 1, identity_norm_layer=None, nd: int = 2, conv_kwargs=None)
- forward(inputs: Tensor) Tensor
- class ConvNeXt(in_channels: int, out_channels: int, block_setting: List[CNBlockConfig], stochastic_depth_prob: float = 0.0, layer_scale: float = 1e-06, block: Callable[[...], Module] | None = None, block_kwargs: dict | None = None, norm_layer: Callable[[...], Module] | None = None, pretrained=False, fused_initial=True, final_layer=None, pyramid_pooling=False, pyramid_pooling_channels=64, pyramid_pooling_kwargs=None, secondary_block=None, nd=2)
- class ConvNeXtBase(in_channels: int = 3, out_channels: int = 0, stochastic_depth_prob: float = 0.1, pretrained: bool = False, nd: int = 2, **kwargs)
ContNeXt Base.
References
- Parameters:
in_channels – Input channels.
out_channels – Output channels. If set to
0, the output layer is omitted.stochastic_depth_prob – Stochastic depth probability. Base probability of randomly dropping residual connections. Actual probability in blocks is given by
stochastic_depth_prob * stage_block_id / (total_stage_blocks - 1.0).pretrained – Whether to use pretrained weights. By default, weights from
torchvisionare used.nd – Number of spatial dimensions.
**kwargs – Additional keyword arguments.
- class ConvNeXtLarge(in_channels: int = 3, out_channels: int = 0, stochastic_depth_prob: float = 0.1, pretrained: bool = False, nd: int = 2, **kwargs)
ContNeXt Large.
References
- Parameters:
in_channels – Input channels.
out_channels – Output channels. If set to
0, the output layer is omitted.stochastic_depth_prob – Stochastic depth probability. Base probability of randomly dropping residual connections. Actual probability in blocks is given by
stochastic_depth_prob * stage_block_id / (total_stage_blocks - 1.0).pretrained – Whether to use pretrained weights. By default, weights from
torchvisionare used.nd – Number of spatial dimensions.
**kwargs – Additional keyword arguments.
- class ConvNeXtSmall(in_channels: int = 3, out_channels: int = 0, stochastic_depth_prob: float = 0.1, pretrained: bool = False, nd: int = 2, **kwargs)
ContNeXt Small.
References
- Parameters:
in_channels – Input channels.
out_channels – Output channels. If set to
0, the output layer is omitted.stochastic_depth_prob – Stochastic depth probability. Base probability of randomly dropping residual connections. Actual probability in blocks is given by
stochastic_depth_prob * stage_block_id / (total_stage_blocks - 1.0).pretrained – Whether to use pretrained weights. By default, weights from
torchvisionare used.nd – Number of spatial dimensions.
**kwargs – Additional keyword arguments.
- class ConvNeXtTiny(in_channels: int = 3, out_channels: int = 0, stochastic_depth_prob: float = 0.1, pretrained: bool = False, nd: int = 2, **kwargs)
ContNeXt Tiny.
References
- Parameters:
in_channels – Input channels.
out_channels – Output channels. If set to
0, the output layer is omitted.stochastic_depth_prob – Stochastic depth probability. Base probability of randomly dropping residual connections. Actual probability in blocks is given by
stochastic_depth_prob * stage_block_id / (total_stage_blocks - 1.0).pretrained – Whether to use pretrained weights. By default, weights from
torchvisionare used.nd – Number of spatial dimensions.
**kwargs – Additional keyword arguments.
MobileNet
- class MobileNetV3Large(in_channels, width_mult: float = 1.0, reduced_tail: bool = False, dilated: bool = False)
- class MobileNetV3Small(in_channels, width_mult: float = 1.0, reduced_tail: bool = False, dilated: bool = False)
Common Modules
- class AdditiveNoise2d(in_channels, noise_channels=1, weighted=True, **kwargs)
- class AdditiveNoise3d(in_channels, noise_channels=1, weighted=True, **kwargs)
- class BottleneckBlock(in_channels, out_channels, kernel_size=3, padding=1, mid_channels=None, compression=4, base_channels=64, norm_layer='BatchNorm2d', activation='ReLU', stride=1, downsample=None, nd=2, **kwargs)
Bottleneck Block.
Typical Bottleneck Block with variable kernel size and an included mapping of the identity to correct dimensions.
References
Notes
Similar to
torchvision.models.resnet.Bottleneck, with different interface and defaults.Consistent with standard signature
in_channels, out_channels, kernel_size, ....Stride handled in bottleneck.
- Parameters:
in_channels – Input channels.
out_channels – Output channels.
kernel_size – Kernel size.
padding – Padding.
mid_channels
compression – Compression rate of the bottleneck. The default 4 compresses 256 channels to 64=256/4.
base_channels – Minimum number of
mid_channels.norm_layer – Norm layer.
activation – Activation.
stride – Stride.
downsample – Downsample module that maps identity to correct dimensions. Default is an optionally strided 1x1 Conv2d with BatchNorm2d, as per He et al. (2015) (3.3. Network Architectures, Residual Network, “option (B)”).
**kwargs – Keyword arguments for Conv2d layers.
- class ConvNorm(in_channels, out_channels, kernel_size=3, padding=1, stride=1, norm_layer=<class 'torch.nn.modules.batchnorm.BatchNorm2d'>, nd=2, **kwargs)
ConvNorm.
Just a convolution and a normalization layer.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels.
kernel_size – Kernel size.
padding – Padding.
stride – Stride.
norm_layer – Normalization layer (e.g.
nn.BatchNorm2d).**kwargs – Additional keyword arguments.
- class ConvNormRelu(in_channels, out_channels, kernel_size=3, padding=1, stride=1, norm_layer=<class 'torch.nn.modules.batchnorm.BatchNorm2d'>, activation='relu', nd=2, **kwargs)
ConvNormReLU.
Just a convolution, normalization layer and an activation.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels.
kernel_size – Kernel size.
padding – Padding.
stride – Stride.
norm_layer – Normalization layer (e.g.
nn.BatchNorm2d).activation – Activation function. (e.g.
nn.ReLU,'relu')**kwargs – Additional keyword arguments.
- class DynamicTanh(normalized_shape, channels_last, alpha_init_value=0.5)
Dynamic Tanh.
Dynamic Tanh (DyT) is a replacement for commonly used Layer Norm or RMSNorm layers [1].
References
- Parameters:
normalized_shape (int or tuple) – Shape of the normalized channels.
channels_last (bool) – If True, expects input in (…, C) format. If False, expects input in (B, C, …) format.
alpha_init_value (float) – Initial value for the learnable scalar alpha.
- extra_repr()
- forward(x)
- class Fuse1d(in_channels, out_channels, kernel_size=1, padding=0, activation='relu', norm_layer='batchnorm1d', **kwargs)
- class Fuse2d(in_channels, out_channels, kernel_size=1, padding=0, activation='relu', norm_layer='batchnorm2d', **kwargs)
- class Fuse3d(in_channels, out_channels, kernel_size=1, padding=0, activation='relu', norm_layer='batchnorm3d', **kwargs)
- class LayerNorm1d(normalized_shape, eps: float = 1e-05, elementwise_affine: bool = True, device=None, dtype=None)
Layer Norm.
By default,
LayerNorm1d(channels)operates on feature vectors, i.e. the channel dimension.- Parameters:
normalized_shape – Input shape from an expected input of size
eps – A value added to the denominator for numerical stability. Default: 1e-5
elementwise_affine – A boolean value that when set to
True, this module has learnable per-element affine parameters initialized to ones (for weights) and zeros (for biases). Default:True.device – Device.
dtype – Data type.
- class LayerNorm2d(normalized_shape, eps: float = 1e-05, elementwise_affine: bool = True, device=None, dtype=None)
Layer Norm.
By default,
LayerNorm2d(channels)operates on feature vectors, i.e. the channel dimension.- Parameters:
normalized_shape – Input shape from an expected input of size
eps – A value added to the denominator for numerical stability. Default: 1e-5
elementwise_affine – A boolean value that when set to
True, this module has learnable per-element affine parameters initialized to ones (for weights) and zeros (for biases). Default:True.device – Device.
dtype – Data type.
- class LayerNorm3d(normalized_shape, eps: float = 1e-05, elementwise_affine: bool = True, device=None, dtype=None)
Layer Norm.
By default,
LayerNorm3d(channels)operates on feature vectors, i.e. the channel dimension.- Parameters:
normalized_shape – Input shape from an expected input of size
eps – A value added to the denominator for numerical stability. Default: 1e-5
elementwise_affine – A boolean value that when set to
True, this module has learnable per-element affine parameters initialized to ones (for weights) and zeros (for biases). Default:True.device – Device.
dtype – Data type.
- class MinibatchStdLayer(channels=1, group_channels=None, epsilon=1e-08)
Minibatch standard deviation layer.
The minibatch standard deviation layer first splits the batch dimension into slices of size
group_channels. The channel dimension is split intochannelsslices. For the groups the standard deviation is calculated and averaged over spatial dimensions and channel slice depth. The result is broadcasted to the spatial dimensions, repeated for the batch dimension and then concatenated to the channel dimension ofx.References
- Parameters:
channels – Number of averaged standard deviation channels.
group_channels – Number of channels per group. Default: batch size.
epsilon – Epsilon.
- extra_repr() str
- forward(x)
- class NoAmp(module: Type[Module])
No AMP.
Wrap a
Moduleobject and disabletorch.cuda.amp.autocastduring forward pass if it is enabled.Examples
>>> import celldetection as cd ... model = cd.models.CpnU22(1) ... # Wrap all ReadOut modules in model with NoAmp, thus disabling autocast for those modules ... cd.wrap_module_(model, cd.models.ReadOut, cd.models.NoAmp)
- Parameters:
module – Module.
- forward(*args, **kwargs)
- class Normalize(mean=0.0, std=1.0, assert_range=(0.0, 1.0))
- extra_repr() str
- forward(inputs: Tensor)
- class ReadOut(channels_in, channels_out, kernel_size=3, padding=1, activation='relu', norm='batchnorm2d', final_activation=None, dropout=0.1, channels_mid=None, stride=1, nd=2, attention=None)
- forward(x)
- class ReplayCache(size=128)
Replay Cache.
Typical cache that can be used for experience replay in GAN training.
Notes
Items remain on their current device.
- Parameters:
size – Number of batch items that fit in cache.
- add(x, fraction=0.5)
Add.
Add a
fractionof batchxto cache. Drop random items if cache is full.- Parameters:
x – Batch Tensor[n, …].
fraction – Fraction in 0..1.
- is_empty()
- class ResBlock(in_channels, out_channels, kernel_size=3, padding=1, norm_layer='BatchNorm2d', activation='ReLU', stride=1, downsample=None, nd=2, **kwargs)
ResBlock.
Typical ResBlock with variable kernel size and an included mapping of the identity to correct dimensions.
References
Notes
Similar to
torchvision.models.resnet.BasicBlock, with different interface and defaults.Consistent with standard signature
in_channels, out_channels, kernel_size, ....
- Parameters:
in_channels – Input channels.
out_channels – Output channels.
kernel_size – Kernel size.
padding – Padding.
norm_layer – Norm layer.
activation – Activation.
stride – Stride.
downsample – Downsample module that maps identity to correct dimensions. Default is an optionally strided 1x1 Conv2d with BatchNorm2d, as per He et al. (2015) (3.3. Network Architectures, Residual Network, “option (B)”).
**kwargs – Keyword arguments for Conv2d layers.
- class ScaledSigmoid(factor, shift=0.0)
Scaled Sigmoid.
Computes the scaled and shifted sigmoid:
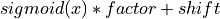
- Parameters:
factor – Scaling factor.
shift – Shifting constant.
- class ScaledTanh(factor, shift=0.0)
Scaled Tanh.
Computes the scaled and shifted hyperbolic tangent:
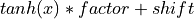
- Parameters:
factor – Scaling factor.
shift – Shifting constant.
- class SelfAttention(in_channels, out_channels=None, mid_channels=None, kernel_size=1, padding=0, beta=True, nd=2)
Self-Attention.
References
- Parameters:
in_channels
out_channels – Equal to in_channels by default.
mid_channels – Set to in_channels // 8 by default.
kernel_size
padding
beta
nd
- forward(inputs)
- class SpatialSplit(height, width=None)
Spatial split.
Splits spatial dimensions of input Tensor into patches of size
(height, width)and adds the patches to the batch dimension.- Parameters:
height – Patch height.
width – Patch width.
- forward(x)
- class SqueezeExcitation(in_channels, squeeze_channels=None, compression=16, activation='relu', scale_activation='sigmoid', residual=True, nd=2)
- forward(inputs)
- class Stride1d(stride, start=0)
- class Stride2d(stride, start=0)
- class Stride3d(stride, start=0)
- class TwoConvNormLeaky(in_channels, out_channels, kernel_size=3, padding=1, stride=1, mid_channels=None, norm_layer=<class 'torch.nn.modules.batchnorm.BatchNorm2d'>, nd=2, **kwargs)
- class TwoConvNormRelu(in_channels, out_channels, kernel_size=3, padding=1, stride=1, mid_channels=None, norm_layer=<class 'torch.nn.modules.batchnorm.BatchNorm2d'>, activation='relu', nd=2, **kwargs)
TwoConvNormReLU.
A sequence of conv, norm, activation, conv, norm, activation.
- Parameters:
in_channels – Number of input channels.
out_channels – Number of output channels.
kernel_size – Kernel size.
padding – Padding.
stride – Stride.
mid_channels – Mid-channels. Default: Same as
out_channels.norm_layer – Normalization layer (e.g.
nn.BatchNorm2d).activation – Activation function. (e.g.
nn.ReLU,'relu')**kwargs – Additional keyword arguments.
Filters
- class BoxFilter2d(in_channels: int, kernel_size, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 0, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'zeros', device=None, dtype=None, odd_padding=True, trainable=False, normalize=True)
Box Filter 2d.
- Parameters:
in_channels – Number of input channels.
stride – Stride.
padding – Padding.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'zeros'.device – Device.
dtype – Data type.
odd_padding – Whether to apply one-sided padding to account for even kernel sizes.
trainable – Whether the kernel should be trainable.
normalize – Whether to normalize the kernel to retain magnitude.
- static get_kernel2d(kernel_size, normalize=True)
- class EdgeFilter2d(in_channels: int, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 1, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'replicate', device=None, dtype=None, magnitude=True, trainable=False, **kwargs)
Edge Filter 2d.
Find edges in an image using the Sobel filter.
- Parameters:
in_channels – Number of input channels.
stride – Stride.
padding – Padding. Default: 1.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'replicate'.device – Device.
dtype – Data type.
trainable – Whether the kernel should be trainable.
magnitude – Whether to compute the magnitude image.
**kwargs – Additional keyword arguments for
cd.models.Filter2d.
- forward(x)
- class Filter2d(in_channels: int, kernel, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 0, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'zeros', device=None, dtype=None, odd_padding=True, trainable=True)
Filter 2d.
Applies a 2d filter to all channels of input.
Examples
>>> sobel = torch.as_tensor([ ... [1, 0, -1], ... [2, 0, -2], ... [1, 0, -1], ... ], dtype=torch.float32) ... sobel_layer = Filter2d(in_channels=3, kernel=sobel, padding=1, trainable=False) ... sobel_layer, sobel_layer.weight (Filter2d(3, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=3, bias=False), tensor([[ 1., 0., -1.], [ 2., 0., -2.], [ 1., 0., -1.]]))
- Parameters:
in_channels – Number of input channels.
kernel – Filter matrix.
stride – Stride.
padding – Padding.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'zeros'.device – Device.
dtype – Data type.
odd_padding – Whether to apply one-sided padding to account for even kernel sizes.
trainable – Whether the kernel should be trainable.
- forward(x: Tensor) Tensor
- reset_parameters()
- class GaussianFilter2d(in_channels: int, kernel_size, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 0, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'zeros', device=None, dtype=None, odd_padding=True, trainable=False, sigma=-1)
Gaussian Filter 2d.
- Parameters:
in_channels – Number of input channels.
kernel_size – Kernel size.
stride – Stride.
padding – Padding.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'zeros'.device – Device.
dtype – Data type.
odd_padding – Whether to apply one-sided padding to account for even kernel sizes.
trainable – Whether the kernel should be trainable.
sigma – Gaussian standard deviation as float or tuple. If it is non-positive, it is computed from kernel_size as
sigma = 0.3*((kernel_size-1)*0.5 - 1) + 0.8.
- static get_kernel2d(kernel_size, sigma=-1)
- class LaplaceFilter2d(in_channels: int, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 0, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'zeros', device=None, dtype=None, odd_padding=True, trainable=False, diagonal=False)
Laplace Filter 2d.
Applies the 3x3 Laplace operator.
References
- Parameters:
in_channels – Number of input channels.
stride – Stride.
padding – Padding.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'zeros'.device – Device.
dtype – Data type.
odd_padding – Whether to apply one-sided padding to account for even kernel sizes.
trainable – Whether the kernel should be trainable.
diagonal – Whether to use a kernel that includes diagonals.
- static get_kernel2d(diagonal=False)
- class PascalFilter2d(in_channels: int, kernel_size, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 0, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'zeros', device=None, dtype=None, odd_padding=True, trainable=False, normalize=True)
Pascal Filter 2d.
Applies a 2d pascal filter to all channels of input.
References
- Parameters:
in_channels – Number of input channels.
kernel_size – Kernel size.
stride – Stride.
padding – Padding.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'zeros'.device – Device.
dtype – Data type.
odd_padding – Whether to apply one-sided padding to account for even kernel sizes.
trainable – Whether the kernel should be trainable.
normalize – Whether to normalize the kernel to retain magnitude.
- static get_kernel1d(kernel_size, normalize=True)
- static get_kernel2d(kernel_size, normalize=True)
- class ScharrFilter2d(in_channels: int, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 0, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'zeros', device=None, dtype=None, odd_padding=True, trainable=False, transpose=False)
Scharr Filter 2d.
Applies the Scharr gradient operator, a 3x3 kernel optimized for rotational symmetry.
References
- Parameters:
in_channels – Number of input channels.
stride – Stride.
padding – Padding.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'zeros'.device – Device.
dtype – Data type.
odd_padding – Whether to apply one-sided padding to account for even kernel sizes.
trainable – Whether the kernel should be trainable.
transpose –
Falsefor kernel,
kernel, Truefor kernel.
kernel.
- static get_kernel2d(transpose=False)
- class SobelFilter2d(in_channels: int, stride: int | Tuple[int, int] = 1, padding: str | int | Tuple[int, int] = 0, dilation: int | Tuple[int, int] = 1, padding_mode: str = 'zeros', device=None, dtype=None, odd_padding=True, trainable=False, transpose=False)
Sobel Filter 2d.
Applies the 3x3 Sobel image gradient operator.
References
- Parameters:
in_channels – Number of input channels.
stride – Stride.
padding – Padding.
dilation – Spacing between kernel elements.
padding_mode – One of
'zeros','reflect','replicate'or'circular'. Default:'zeros'.device – Device.
dtype – Data type.
odd_padding – Whether to apply one-sided padding to account for even kernel sizes.
trainable – Whether the kernel should be trainable.
transpose –
Falsefor kernel, Truefor kernel.
- static get_kernel2d(transpose=False)
- class UpFilter2d(module, scale_factor: int = 2)
Upsample Filter 2d.
This Module performs the upsampling step of a typical image pyramid. First, it upsamples the input Tensor by injecting zeros as columns and rows, then it applies the given
module, which could be for example acd.models.PascalFilter2d.- Parameters:
module – Filter module.
scale_factor – Scale factor.
- forward(x: Tensor) Tensor
Normalization
- class PixelNorm(dim=1, eps=1e-08)
Pixel normalization.
References
https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (“Local Repose Norm”)
- Parameters:
dim – Dimension to normalize.
eps – Epsilon.
- forward(x)
Losses
- class BoxNpllLoss(factor=10.0, sigmoid=False, min_size=None, epsilon=1e-08, size_average=None, reduce=None, reduction: str = 'mean')
- forward(uncertainty: Tensor, input: Tensor, target: Tensor) Tensor